- Published on
Creating an AI assistant with your own data

Large Language Models (LLM) are a class of machine learning models that are trained on large amounts of text data to generate human-like text.
One of the applications of Large Language Models LLM models is natural language processing, or NLP, that deals with understanding and generating natural language texts. NLP can enable many intelligent applications, such as chatbots, voice assistants, text analytics, and more.
The power of LLM models comes from their training on massive datasets, covering various topics and fields. This allows them to learn general patterns and knowledge about natural language and the world.
You interact with the LLM models through a prompt, which is a text input which the model uses as the basis for generating the response. The prompt can include a system message to prime the model with instructions and other constraints to guide the model's output.
An example of a system message can be as follows -
You are an AI assistant for summarizing news articles.
Generate a summary of the article below -
{{article}}
The {{article}} is a placeholder for the actual article text that you provide to the model.
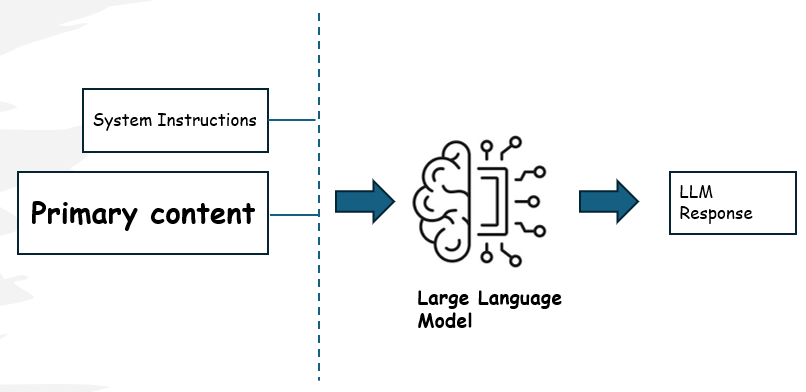
LLM models have some limitations that you should be aware of -
For example, LLM models are indeterministic, which means that they can generate different outputs for the same input. This can lead to inconsistency and unpredictability in the results.
Another limitation is hallucination, which means that LLM models can generate texts that are not based on facts or logic, but on their own learned biases and assumptions. This can lead to false or misleading information in the outputs.
LLM models are trained on public data and are not updated with the latest data and events. They may also lack the specific context or domain knowledge that your application needs.
This can lead to texts that are generic, vague, or irrelevant.
Techniques to Improve LLM response
Some techniques that you can use to enhance the quality and reliability of the texts generated by LLM models are -
Provide data - Provide use-case specific data to LLM models, so that they can generate texts that are relevant to your domain and context.
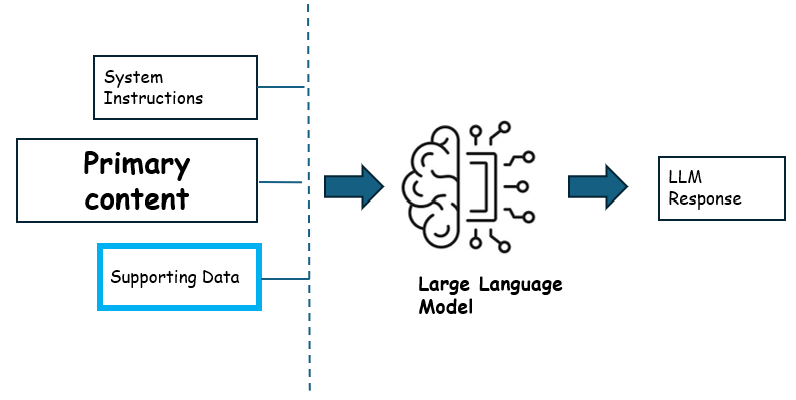
For example, if you want to an AI assistant help the customers with questions on the products, you can provide the LLM models with information about the products in the store, such as their features, specifications, and prices.
The prompt will then look like this -
You are an AI assistant for a bike store to help the customer with questions on the products. The answers should be based on the information provided about the products below - {{products}} {{injected_prompt}}Note that the
{{products}}and{{injected_prompt}}are placeholders for the actual data that you provide to the model.The
{{products}}can be a list of products in the store, such as bikes, helmets, and accessories, along with their features, specifications, and prices. In the later section we will see how to extract the relevant product information from the external sources and provide it to the LLM models.Show and tell - Provide sample inputs and outputs that can show your LLM models what kind of texts you want them to generate. This would steer the LLM models towards generating texts that are similar to the examples you provide.
In the AI assistant mentioned above, you can give a few examples of how such questions and answers look like, and your LLM models will try to follow the same style and tone.
The updated prompt will then look like this -
You are an AI assistant for a bike store to help the customer with questions on the products.The answers should be based on the information provided about the products below - {{products}} The products should be in table format with columns for the product name, features, specifications, and prices. [user]: I want a bike that is good for commuting in the city and has a comfortable seat. What do you recommend ? [assisant]: You can try the City Commuter bike. It has a comfortable seat and is perfect for city commuting. The price is $500. Would you like to know more about it ? | Product Name | Features | Specifications | Price | | ------------- | ---------------- | --------------------------- | ----- | | City Commuter | Comfortable seat | Suitable for city commuting | $500 |Fine-Tune Models - Another technique is to use fine-tuning, which is a process of re-training your LLM models on a smaller and more specific dataset that is related to your domain.
For example, if you want to create medical reports based on patient data, you can fine-tune your LLM models on a dataset of medical texts and terms, so that they can learn the right vocabulary and format for such reports.
One drawback of fine-tuning LLM models is that it requires a lot of computational resources and time, especially if you want to fine-tune on large and complex datasets.
Creating an AI Assistant
Let's apply the techniques we talked about to an AI assistant for a bike store. The assistant should help the customer by using natural language processing and knowledge retrieval to find out what the customer wants and recommend bikes that match their features and criteria.
Some example user queries are -
I want a bike that is good for commuting in the city
and has a comfortable seat. What do you recommend?
I like the color blue and I want a bike that
has a blue frame. Can you show me some options?
To get answers to these questions, the LLM models needs to be made aware of the bike store's inventory. The LLM models can then use this information to generate relevant and accurate responses to the customer's queries.
LLM models have a fixed number of tokens that they can process at a time. This means that if you use too much data to augment your prompt, you may exceed the token. On the other hand, if you use too little data, you may not provide enough relevant and useful details for your LLM models to generate high-quality outputs.
Retrieval Augmented Generation (RAG) is a popular pattern for incorporating specific data or context into language models. It involves using a search engine or a knowledge base to find additional texts that are related to your input, and then using those texts to enhance your LLM models' outputs.
The search can be performed using full-text search, semantic search, or hybrid search.
Full-text search looks for specific keywords or phrases in the texts, while semantic search looks for texts that are similar in meaning to your input.
Hybrid search combines both approaches and may work better in some cases. The type of search you choose depends on the nature of your data and use case requirements.
The search results are ranked and filtered to select the most relevant texts, which are then used to augment your LLM models' inputs.
Embedding is a method of transforming the semantic meaning of data into a vector. A vector is a numerical representation of a text's meaning and similarity. Because the vector representation reflects the semantic meaning, it enables searching for similar data based on the semantic meaning of the data rather than the exact text.
In the bike store AI assistant scenario, we can embed the bike description and other relevant fields, such as the colour, the brand, or the customer rating, into vectors and store them in a vector database. Then, when a user asks for a bike recommendation, we can run vector search on the vectorized data to find the most similar bikes to the user's criteria.
The steps involved in implementing the RAG pattern are as follows:
Pre-Processing

- The data may be unstructured and spread across multiple sources. The data is ingested into a vector database.
- The data that is relevant to the user query is vectorized using an embedding model. The vector embedding is stored as a vector field within its source record.
- The vector columns are indexed and optimized for fast search and retrieval.
Run-time
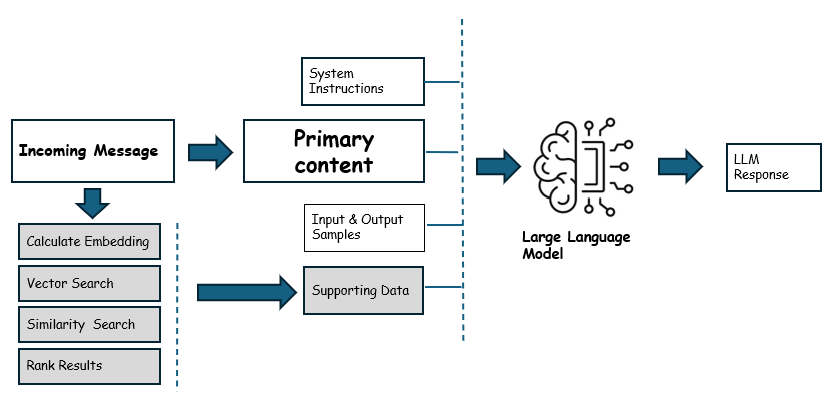
- The user query is vectorized using the same embedding model.
- The vectorized query is used to search the vector database for similar vectors.
- The search results are ranked and filtered to select the most relevant records.
- The selected records are used to augment the LLM model's input.
- The updated prompt is used to generate the response.
Takeaway
The RAG pattern is a powerful technique for introducing context data into the LLM models. This article outlines the basic concepts of how to build an AI assistant for your own data.
You can also build more advanced AI assistants by introducing plugins or tools that would be consumed in runtime to perform specific tasks. The tasks can be anything like searching the web, fetching data from a database dynamically, performing calculations, etc. There are many frameworks like Langchain, Sematic Kernel etc. that can be used to orchestrate the workflow.
The field of NLP applications is evolving rapidly, and there are many opportunities for innovation and creativity in this space !!