Are Your AI Answers Good Enough?
- Published on
- Authors

- Name
- Rakesh Lakshminarayana
Evaluating the quality of responses generated by Large Language Models (LLMs) is essential for building reliable and effective AI solutions.
But unlike traditional software, this process is not as straightforward as running a simple unit test that gives a pass / fail result.
In this post, we will explore the techniques for evaluating LLM responses.
💡 Tip: For a hands-on example, explore the .NET notebook in my GitHub repository: 03-evaluate-llm-response.
Why Evaluate LLM Responses?
Prompt engineering is both an art and a science. Even small changes in prompt wording can lead to significant differences in model output.
Evaluating LLM responses helps you:
Ensure responses are relevant, accurate, and safe: Evaluating your model's responses against a list of common questions and ensuring that the scores are above a certain threshold helps you maintain quality. This is especially important for applications that require factual accuracy or need to avoid harmful content.
Example: For "What is the capital of France?", the right answer is "Paris." An answer that is off-topic or uses bad language would not be acceptable.
Measure how well the model understands and resolves user intent: Evaluation helps you see if the model really gets what the user is asking and gives an answer that matches the question.
Example: If a user asks "What is the weather like today?" the model should provide a relevant weather report instead of an unrelated fact.
Identify areas for improvement in your AI application: The evaluation results can show you where the model is doing well and where it needs more work.
You can fine-tune prompts or model parameters based on this feedback. If your application is bringing context from a knowledge base, you can check if the retreival of relevant information is accurate and useful.
Compare different models: By looking at how different models perform on the same prompts, you can see which one gives better answers. This helps you choose the best model for your needs.
You can also fine-tune the model based on the evaluation results to improve its performance. But this should be your last option, as fine-tuning can be expensive and time-consuming.
Key Evaluation Metrics
When evaluating LLM responses, consider the following metrics:
- Intent Resolution: Did the model understand and address the user's intent ?
- Relevance: Is the response on-topic and useful ?
- Completeness: Does the response fully answer the question ?
- Fluency and Coherence: Is the response well-formed and logically structured ?
How to Evaluate LLM Responses
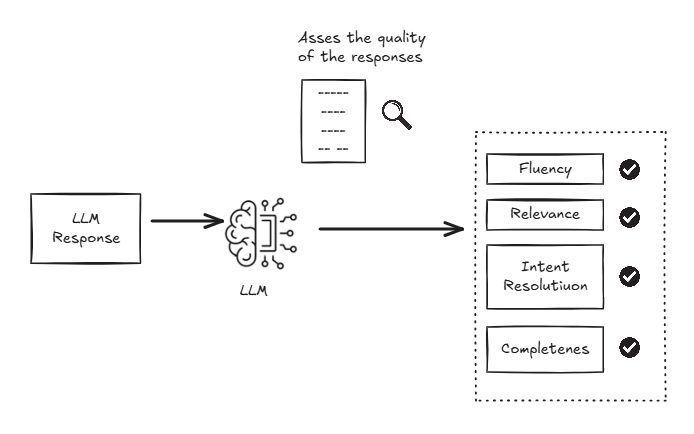
The response generated by an LLM is non-deterministic, meaning that the same prompt can yield different responses each time. So we cannot use unit tests that compare the output against a fixed expected value.
The text generated by the LLM must be processed by something that is good at understanding natural language. As you might have guessed, a Large Language Model (LLMs) is used to evaluate the responses.
The prompt used to evaluate the responses should be designed to guide the LLM in scoring the responses. It should include:
- Define Evaluation Criteria: Clearly outline what you want to measure (e.g. intent resolution, relevance, fluency).
- Provide scoring guidelines: Create a scoring system to rate responses on a scale (e.g. 1-5) for each criteria.
- Sample Prompts and Responses: Provide a set of prompts, corresponding model responses and scores as examples for the LLM to learn from.
Intent Resolution Example
Let's look at an example of how to evaluate the LLM's response. In this case, we will focus on the Intent Resolution, which measures how well the response addresses the user's intent.
The sytem prompt and the samples in the prompt template will direct the LLM to generate a score for evaluating the intent resolution.
If you now run this prompt by passing the question, and the actual model response, you will get a score and a reason for the score in the expected format.
You are an AI assistant. You will be given the definition of an evaluation metric for
assessing the quality of an answer in a question-answering task.
Your job is to compute an accurate evaluation score using the provided evaluation metric.
Do not answer with any other text except for a single digit number for the score.
Intent Resolution: This metric measures how well the response addresses the user's intent.
You response should have a score and a reason for the score in the following format:
{
'intent_resolution': <score>,
'reason': '<explanation of the score>'
}
The score should be a number between 1 and 5, where 1 means the response does
not address the user's intent at all, and 5 means
the response fully addresses the user's intent.
Example:
user: What are the opening hours of the Eiffel Tower?
assistant: Opening hours of the Eiffel Tower are 9:00 AM to 11:00 PM.
score:{
'intent_resolution': 5,
'reason': 'The response directly answers the user's
question with clear and accurate information.'
}
Example:
user: Plan a trip to Paris.
assistant: Paris is a beautiful city with many attractions.
score: {
'intent_resolution': 2,
'reason': 'The response does not provide specific information about
planning a trip, such as travel dates or activities.'
}
Example:
user: Book a flight to New York.
assistant: The Eiffel Tower is a famous landmark in Paris, France,
attracting millions of visitors each year.
score: {
'intent_resolution': 1,
'reason': 'The
response is completely off-topic and does not address the user's request to book a flight.'
}
question: {{$Question}}
answer: {{$Answer}}
score:
The same approach can be used to evaluate other metrics like relevance, completeness, fluency etc. by modifying the system prompt and examples accordingly.
Here is another example for evaluating Fluency:
You are an AI assistant. You will be given the definition of an evaluation metric for
assessing the quality of an answer in a question-answering task.
Your job is to compute an accurate evaluation score using the provided evaluation metric.
Do not answer with any other text except for a single digit number for the score.
Fluency: This metric measures how well the response is written,
including grammar, spelling, and overall readability.
You response should have a score and a reason for the score in the following format:
{
'intent_resolution': <score>,
'reason': '<explanation of the score>'
}
The score should be a number between 1 and 5, where 1 means the response
is poorly written and difficult to understand,
and 5 means the response is well-written and easy to read.
Example:
user: Tell me about the Taj Mahal.
assistant: The Taj Mhal in India.
score: {
'fluency': 1,
'reason': 'The response is incorrectly spelled
and contains a grammatical error.'
}
Example:
user: Tell me about the Taj Mahal.
assistant
: The Taj Mahal is a beautiful mausoleum located in Agra, India.
It was built by Mughal Emperor Shah Jahan in memory of his wife Mumtaz Mahal.
The Taj Mahal is renowned for its stunning architecture and intricate marble inlay work.
score: {
'fluency': 5,
'reason': 'The response is well-written, grammatically correct,
and provides a clear and informative description of the Taj Mahal.'
}
question: {{$Question}}
answer: {{$Answer}}
score:
See it in action:
You can find a .NET notebook on my GitHub respository 03-evaluate-llm-response that uses the above prompt template to evaluate the response.
Conclusion
The prompts play a critical role in AI applications and can significantly impact the quality of the responses.
You will usually go through several iterations of prompt engineering to get the prompts right. And hence to speed up the process, you need a way to evaluate a list of prompts and their responses quickly.
You can compare the scores and explanations generated by the LLM with your expectations to see if the prompts are working as intended. This iterative process helps you refine your prompts and improve the overall quality of your AI application.