- Published on
Integrating external tools with Large Language Models

A Virtual Assistant can assist users in answering questions, providing information and performing tasks.
In the past, the virtual assistants were built using predefined rules and templates. This approach posed limitations to the number of tasks that the virtual assistant could perform and the quality of the responses it could generate.
With the advancements in Natural Language Processing (NLP), it is now possible to build virtual assistants that can understand and respond to natural language queries. This requires understanding the intent of the user query, extracting key information from the query, executing tasks, and generating appropriate responses.

The LLM models can understand and respond to natural language queries. They can do this because they have been trained on massive amounts of text data. They use a type of machine learning called deep learning to understand how the words relate to each other and generate responses. This is a powerful capability that enables LLM models to produce human-like text and carry on conversations with users.
However, understanding and responding with natural language is not enough for building the next generation of virtual assistants. The virtual assistants also need to be able to perform tasks that require more than just text generation. They should also be able to execute the tasks that the users ask them to perform like solving math problems, ordering food, scheduling a meeting, or booking a flight. These tasks involves using external tools or plugins that provide specialized functionality and data.
This article discusses on the foundation concepts of integrating external tools or plugins with LLM models to create a robust solution for virtual assistants.
Using LLM Models in your Application
The LLM models can be consumed by making an API request to the Chat Completion API.
The user query is sent to the LLM model through the API request. The LLM model processes the query and generates a response based on the context and the query. The response is then sent back to the user.
This is fundamentally how the LLM models are used in applications. The API also provides additional configuration options to customize the behavior of the LLM model like the maximum length of the response, the temperature of the sampling etc.
Integration of External Tools or Plugins with LLM Models
There are language specific libraries available to interact with the Chat Completion API. The API provides support to introduce tools in the API request. This feature known as Function Calling enables LLMs to interact with the external systems.
Register tools
How do we make the LLM aware of the external tools that are available for use?
The Chat Completion API provides additional arguments to register one or more tools. At a minimum, the tools should have a name, description, and schema. The schema describes the input parameters and the output format of the tool.
Tool Selection
How can the LLM determine which tool to use for a given task?
The LLM model intelligently selects the appropriate tool to accomplish a given task. The description of the tool is crucial for the LLM model to determine which tool to use. It may also be necessary to fine-tune the LLM model to determine the tool for more complex use cases.
Calling Tools
How can you invoke the tool with the necessary input data?
The model will process the user query and decides to use the tool. It prepares the input data for the tool in the expected format. It can do this by using the schema of the tool provided in the API request. The API returns the response of the function to be called along with the input arguments. The host application uses this response and invokes the function.
Read Tool Response
How do you interpret the output data from the tool and use it to generate a response?
The output from the tool is again sent to the LLM model. The LLM model uses the schema of the tool to interpret the output data and generate the final response.
The whole process for interacting with external tools can be broken down into two main steps:
Phase 1 - Determine the tool to use
In the first phase, the user query is sent to the LLM model along with the available tools. The model analyzes the query and determines the tool required to process the request. It returns the response with the details of the tool to be used and the input parameters required for the tool.
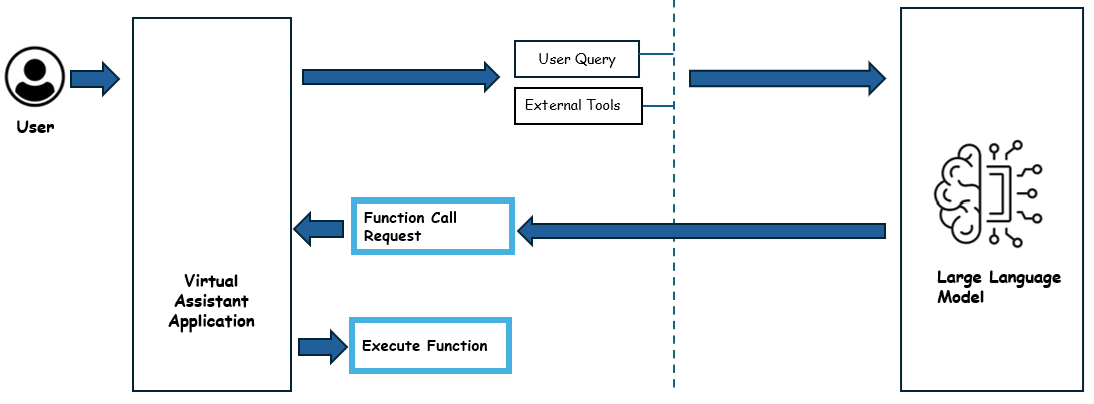
Phase 2 - Execute the tool and generate the response
In the next phase, the host application calls the tool with the input data supplied by the model in the previous step . The response from the tool is again sent to the LLM model. The LLM model uses this data to generate the final response to the user query.
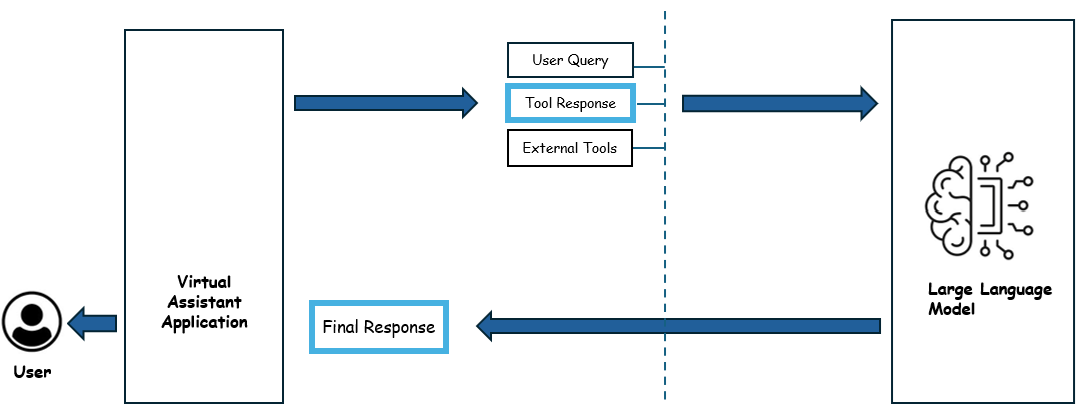
This process can repeat multiple times depending on the complexity of the task and the number of tools required to complete the task. The host application is reponsible to orchestrate the interaction between the LLM model and the external tools.
A Sample Use Case
Let's consider a simple use case where the user asks the virtual assistant to get the current weather in a specific location. The workflow below shows the steps involved in processing the user query and generating the response -
Step 1: The user asks the virtual assistant "What's the current weather in New Delhi?"
Step 2: The weather tool calls the LLM model with the user query. It sends the tool "get_current_weather" with the information about the input and output schema.
Step 3: The LLM model processes the query and determines that the user wants to get the current weather for a specific location. The location of interest is extracted from the query. The LLM model is aware of the tool "get_current_weather" that can perform this task. It sends a response with the tool and the required input parameters.
Step 4: The weather tool uses the input data and runs the tool to get the current weather for the given location. The weather forecast is a data that contains information such as temperature, humidity, precipitation, wind, etc is sent back to the LLM model.
Step 5: The LLM model interprets the weather information and generates a response to the user. The response can be "It is currently 30 degrees Celsius in New Delhi with clear skies and a light breeze." The response is structured based on the user query and the instructions provided in prompt.
Conclusion
Function calling is a game-changer by allowing the LLMs to interact with the real world systems.
The integration to any external system can be acheived by simply publishing an API layer to interact with the system capabilities. This opens up a wide range of possibilities for building virtual assistants that can perform complex tasks and provide more value to the users.