- Published on
Extending RAG with database tools
In my previous post Creating an AI assistant with your own data, I discussed the concept of using a Retrieval-Augmented Generation (RAG) approach to create an AI assistant that can answer questions based on your own data.
Retrieving the relevant records that has the same semantic meaning as the user query will not be sufficient for all use cases.
In this post, I will discuss about the scenarios where we need more than just semantic search to answer the user queries. And one of the ways to solve those problems.
Where does semantic search fall short ?
In the example below, the {{products}} variable contains information about various bikes, including their features, specifications, and prices.
This data is fetched dynamically from the database and passed to the LLM as context. The records fetched from the database have the same semantic meaning as the user query.
The LLM is then prompted with the records to answer user queries.
You are an AI assistant for a bike store to help the customer
with questions on the products.The answers should be based on the information
provided about the products below -
{{products}}
The products should be in table format with columns for the product name,
features, specifications, and prices.
Here is an example of how the model can respond to a user query:
[user]: I want a bike that is good for commuting in the city
and has a comfortable seat. What do you recommend ?
[assisant]: You can try the City Commuter bike.
It has a comfortable seat and is perfect for city commuting.
The price is $500. Would you like to know more about it ?
| Product Name | Features | Specifications | Price |
| ------------- | ---------------- | --------------------------- | ----- |
| City Commuter | Comfortable seat | Suitable for city commuting | $500 |
While this approach works for answering most of the user queries, it would fall short when the user asks for any questions that would require a more specific set of records to be fetched.
For example, think of the following questions from the user -
[user]: What bikes are available for mountain biking under $1000 ?
[user]: Show me the list of top selling bikes in the last 6 months.
[user]: What is the price of the model Trek Domane SLR 7 ?
In these cases, the semantic search would not work. We need a custom handler to understand the user's intent and then query the database to fetch the relevant records by using the keywords in the user query.
Using Database Plugin to handle specific queries
To support the above use cases, we can use a database plugin to handle specific scenarios that require more than just semantic search. The database plugin will have functions to support the following operations:
- Filtering: For example, if the user asks for the best bikes for mountain biking under $1000, the tool can filter the database records based on the specified criteria (e.g. type of bike and price range).
- Aggregation: If the user wants to see the top-selling bikes in the last six months, the tool can aggregate sales data and return the relevant records.
The system prompt to the LLM will look like this -
You are an AI assistant for a bike store to help the customer with questions on the products.
The answers should be based on the information provided about the products below -
{{products}}
The products should be in table format with columns for the product name,
features, specifications, and prices.
The following functions are available to you to help answer the user queries -
- **get_bike_price**: Returns the price of a bike based on the model name.
- **get_bikes_by_type**: Returns a list of bikes based on the type of bike and price range.
- **get_top_selling_bikes**: Returns the top selling bikes in the last 6 months.
How does the LLM know when to use the database plugin ?
The system prompt will include the functions available to the LLM. The LLM will then use its reasoning capabilities to determine when to use the database plugin based on the user query.
The function name and the parameters should have good descriptive names so that the LLM can understand the intent behind the function. You can also provide a brief description of the function to help the LLM understand the purpose of the function.
How does the LLM pass the parameters to the database plugin ?
The LLM response will be in a standard format that includes the function name and the parameters to be passed to the database plugin.
For example, if the user asks for the price of a bike, the LLM response will look like this -
[user]: What is the price of the model Trek Domane SLR 7 ?
[assistant]: The price of the model Trek Domane SLR 7 is $500.
{
"function": "get_bike_price",
"parameters": {
"model_name": "Trek Domane SLR 7"
}
}
Here is the sequence of events that will happen when the user asks for the price of a bike -
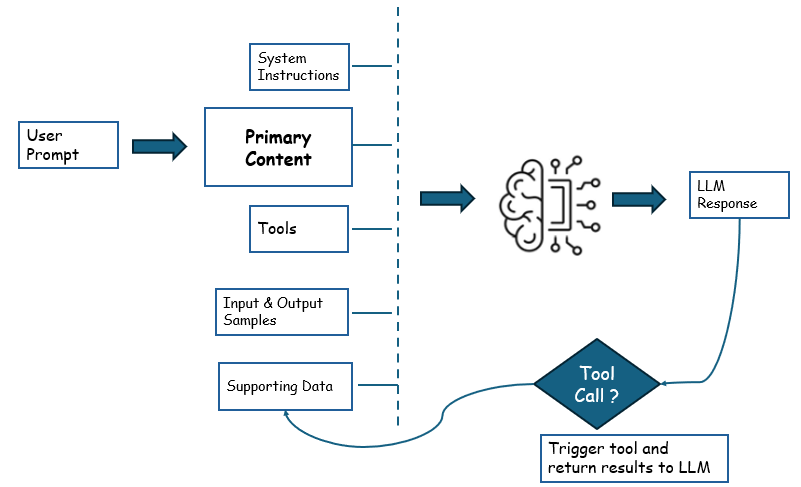
Step 1: The user asks for the price of a bike.
Step 2: The LLM recognizes that this is a specific query that requires the use of the database plugin.
Step 3: The LLM generates a response that includes the function name and the parameters to be passed to the database plugin.
Step 4: The application parses the LLM response and calls the database plugin with the specified function and parameters.
Step 5: The database plugin executes the query and retrieves the relevant data from the database.
Step 6: The result from the database plugin is returned to the LLM, along with the history of the conversation.
Step 7: The LLM generates a final response to the user based on the result from the database plugin.
Step 8: The user receives the formatted response, such as a table or summary, based on the query.
See it in action:
You can find a .NET notebook on my GitHub respository 01-semantic-kernel-function-calling that demonstrates how function calling works using Semantic Kernel.
The notebook example uses an in-memory database to simulate the database plugin with functions to handle the specific queries.
Conclusion
In this post, we looked at how the RAG (Retrieval-Augmented Generation) pattern can be extended using a database plugin to handle queries that go beyond what semantic search alone can manage.
By using a database plugin, we could execute custom queries and retrieve more targeted data. The approach is not just limited to fetching data from a database. You can also use it to call external APIs or perform any other custom operations to fetch the relevant data.
That said, this approach does come with some limitations. It only supports a fixed set of query types, and each new type requires adding a dedicated function to the plugin.
This setup works well when the number of supported queries is small and clearly defined. As the variety of user queries grows, this method becomes harder to scale. To address that, we will need a way to generate database queries dynamically based on the user’s input rather than relying on predefined functions.